大数据简介、Hadoop 起源以及 Google 三大论文介绍
#编程技术 2020-11-06 17:07:00 | 全文 3256 字,阅读约需 7 分钟 | 加载中... 次浏览👋 相关阅读
- github 大佬教你搭建在线代理也能访问谷歌,傻瓜式教程
- 用 Cloudflare Workers 免费反代任意网站,可做谷歌镜像
- Google 中文搜索结果屏蔽黑名单
- 免费 GoogleDrive 无限容量团队盘
- 巧用 Google 官方网页载入速度检测工具 Google page speed 改善网站加载速度
本文主要简单介绍下大数据、Hadoop 起源以及 Google 三篇论文
一、什么是大数据?
1PB 够大吗?
如果你没有直观印象,可以联想一下你的电脑硬盘容量,标配是 500G-1TB,大部分人用了一两年,可能这部分容量都没用完。而 1PB=1024TB=1048576GB。
在实际中,一个小有名气的游戏一天的数据量就在数十 TB 左右,甚至更多。
如果你以为 PB 单位已经是最大了?那就大错特错了!!!!

在 PB 之上,还有 EB(Exabyte 百亿亿字节 艾字节),ZB(Zettabyte 十万亿亿字节 泽字节),YB(Yottabyte 一亿亿亿字节 尧字节),而这些单位也只是为了方便统计海量数据所给出的当前单位,在未来还可能出现更大的单位。

当然,大数据并不只是数据量大而已,它还有其他更深的含义。
对于大数据,麦肯锡全球研究所给出的定义是:
“ 一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合。”
大数据具有五大特点,称为 5V。
-
多样(Variety) 大数据的多样性是指数据的种类和来源是多样化的,数据可以是结构化的、半结构化的以及非结构化的,数据的呈现形式包括但不仅限于文本,图像,视频,HTML页面等等。
-
大量(Volume) 大数据的大量性是指数据量的大小,这个就是上面笔者介绍的内容,不再赘述。
-
高速(Velocity) 大数据的高速性是指数据增长快速,处理快速,每一天,各行各业的数据都在呈现指数性爆炸增长。在许多场景下,数据都具有时效性,如搜索引擎要在几秒中内呈现出用户所需数据。企业或系统在面对快速增长的海量数据时,必须要高速处理,快速响应。
-
低价值密度(Value) 大数据的低价值密度性是指在海量的数据源中,真正有价值的数据少之又少,许多数据可能是错误的,是不完整的,是无法利用的。总体而言,有价值的数据占据数据总量的密度极低,提炼数据好比浪里淘沙。
-
真实性(Veracity) 大数据的真实性是指数据的准确度和可信赖度,代表数据的质量。
1、 大数据核心的问题有:
1、海量数据如何存储? 2、海量数据如何计算?
2、 大数据技术主要解决以上两个问题。举两个例子:
1、大型电商网站的商品推荐:海量的历史的售卖数据如何存储?如何从海量的历史售卖数据中计算出盈利最大化的数据推荐给用户? 2、天气预报:海量的天气数据如何存储?如何从海量的历史数据中计算预测出未来的天气?
大数据的意义不仅仅在于生产和掌握庞大的数据信息,更重要的是对有价值的数据进行专业化处理。
人类从来不缺数据,缺的是对数据进行深度价值挖掘与利用。可以说,从人类社会有了文字以来,数据就开始存在了,现在亦是如此。这其中唯一改变的是数据从产生,到记录,再到使用这整个流程的形式。

二、传统数据处理过程与大数据体系
随着数据库的增大,传统的数据处理无论是存储数据的能力还是处理数据的能力都瓶颈渐显。而大数据的诞生更好地处理了以上两个问题。传统数据处理体系与大数据体系的区别如下图:
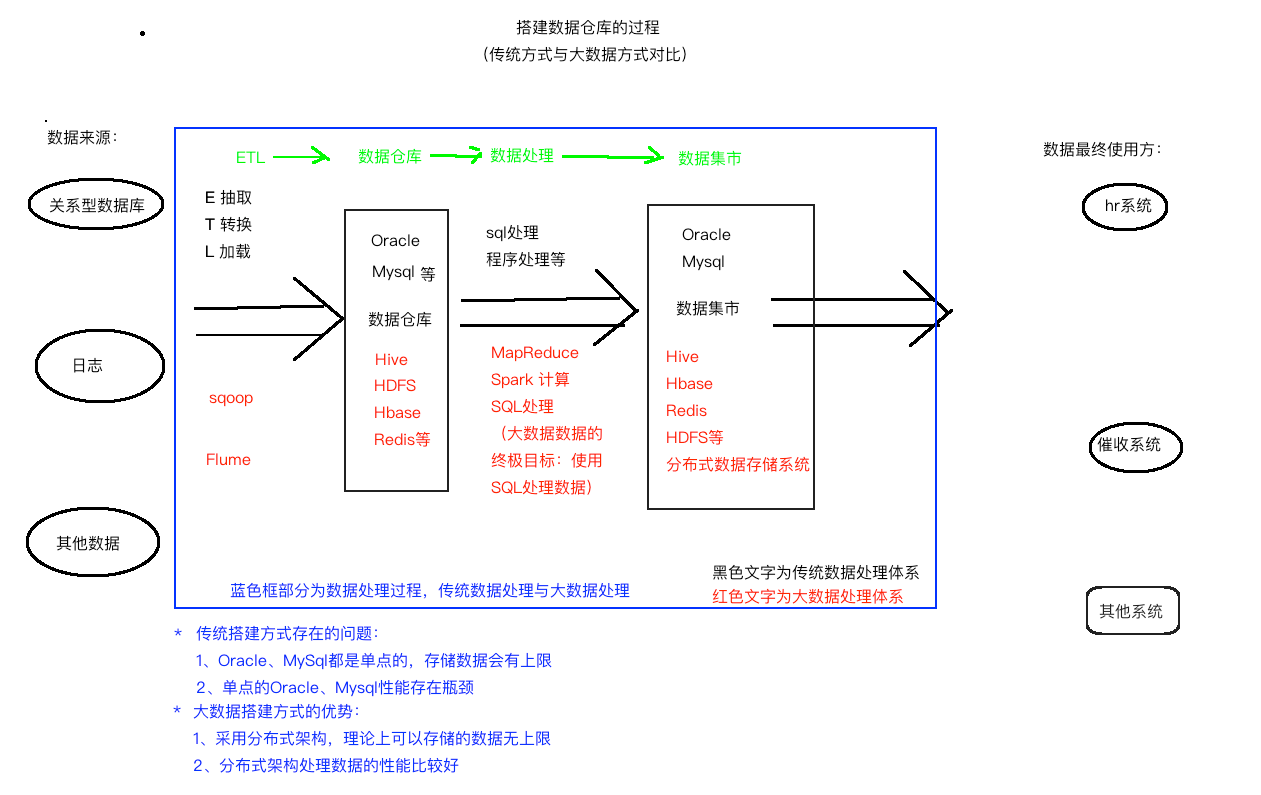
** OLTP 与 OLAP **
- OLTP:Online Transaction Processing 联机事务处理,针对小数据进行增删改。如银行转账。
- LOAP: Online Analytic Processing 联机分析处理,针对大数据的分布式处理,通常为 select(分析).数据仓库是一种 OLAP 的实现。MapReduce、Spark 可以看成是数据仓库的一种解决方案。
三、Google 引爆大数据时代的三篇论文
谈到大数据,就不得不提 Google 的三驾马车:Google FS、MapReduce、BigTable。虽然 Google 没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文,奠定了风靡全球的大数据算法的基础!
1、《Google-File-System》
一个面向大规模数据密集型应用的、可伸缩的分布式文件系统;
中文翻译版:http://blog.csdn.net/xuleicsu/archive/2005/11/10/526386.aspx 中文版下载地址: https://pan.baidu.com/s/1i3verZJ
2、《Google-MapReduce》
一种处理和生成超大数据集的分布式计算模型;
中文翻译版:http://blog.csdn.net/active1001/archive/2007/07/02/1675920.aspx 中文版下载地址: https://pan.baidu.com/s/1hq7XBI8
3、《Google-BigTable》
一个用来处理海量数据的分布式、结构化数据存储系统;
中文翻译版:http://blog.csdn.net/accesine960/archive/2006/02/09/595628.aspx 中文版下载地址: https://pan.baidu.com/s/1eQxmrVc
谷歌三大论文(中英)百度云链接: https://pan.baidu.com/s/1nnn9vu41T9ARrRtJLBhV9Q 提取码: 6666
3.1 分布式文件系统的体系结构
** 3.1.1 传统的文件系统存在如下问题:**
- 硬盘不够大。
- 数据存储单份,比较危险。
而 Google 提出的 GFS(Google File System)思想能解决以上问题。GFS 核心的思想是硬盘横向扩展以及数据冗余。
** 3.1.2 GFS 的优点:**
- 理论上能存储无限数据,因为硬盘可以横向扩展。
- 容错性,数据冗余多份,多份数据同时损坏的概念几乎为零。
- 存储大数据的性能比传统关系型数据库好。
** 3.1.3 分布式文件系统 HDFS 体系结构如下图:**
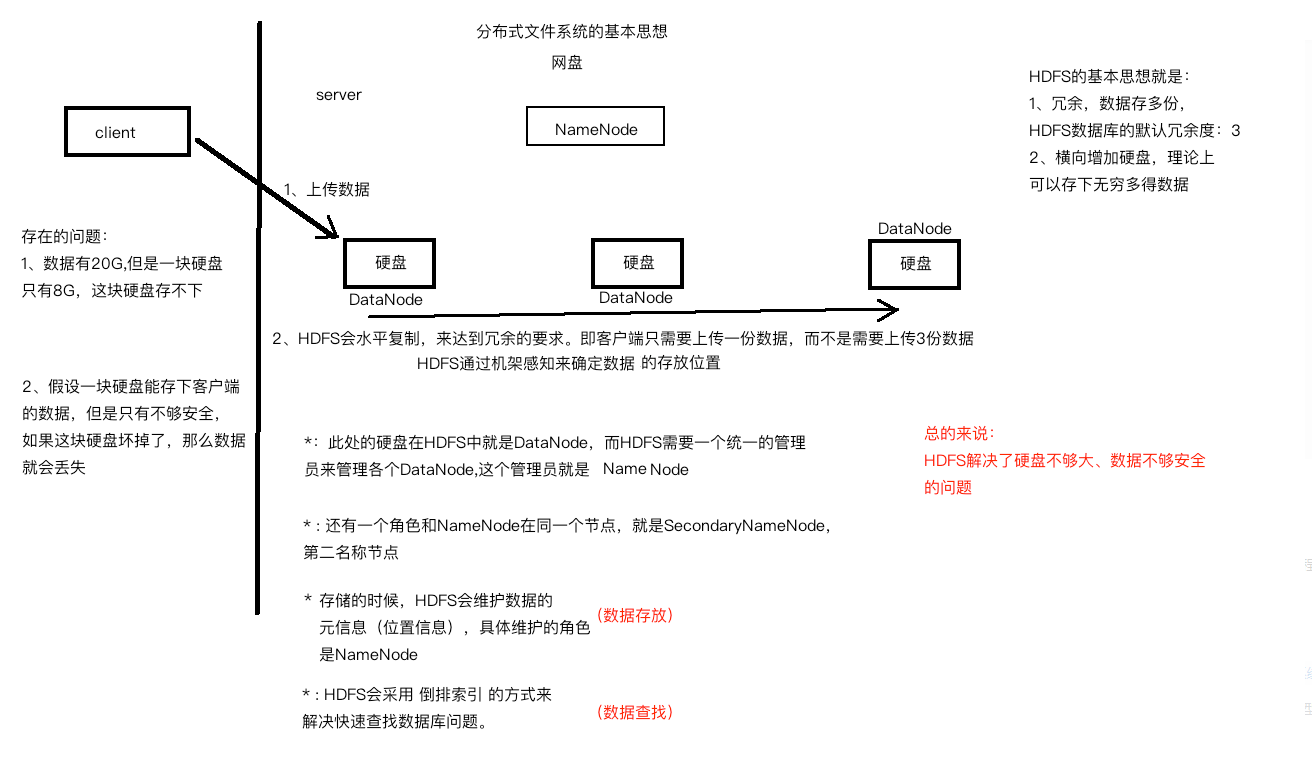
其中上传数据到分布式文件系统的基本过程如下: 1、客户端上传数据块到其中一个硬盘。 2、分布式文件系统会根据机架感知计算出存储数据库的位置,通过水平复制冗余多份数据。
那么何为机架感知?如下图:
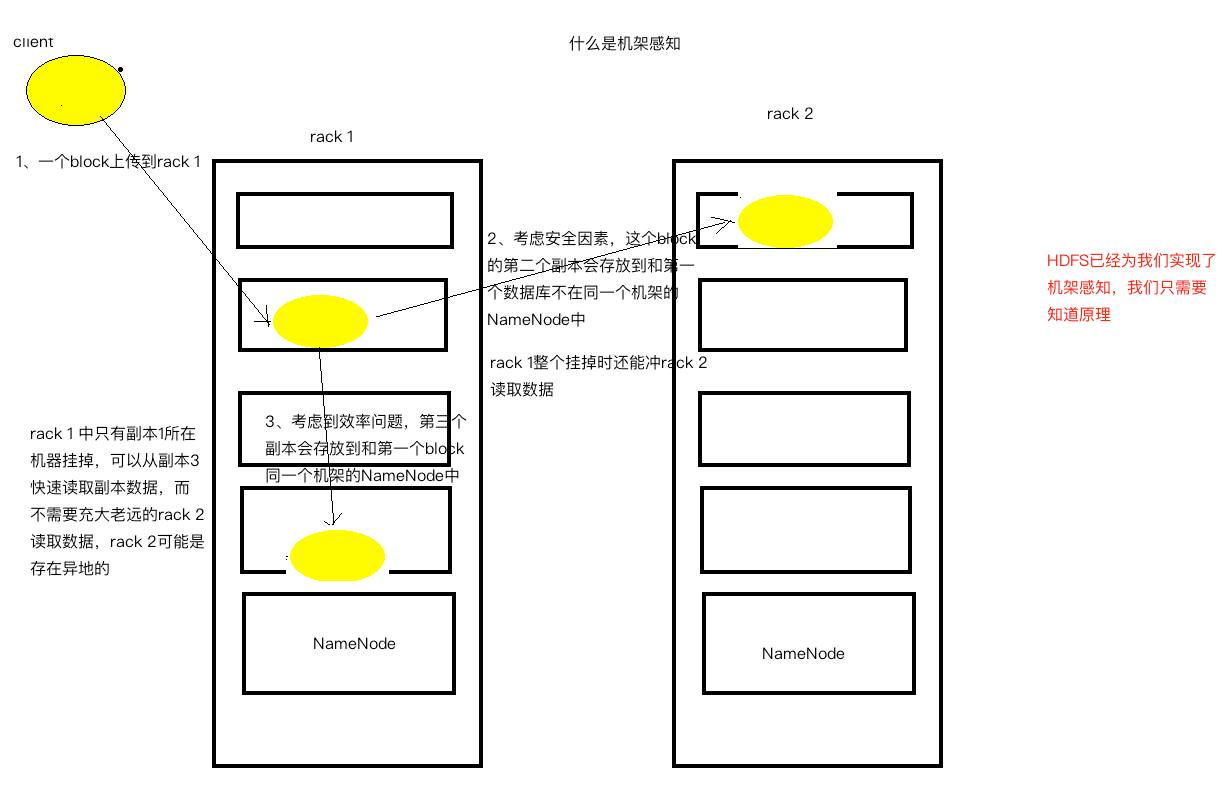
** 3.1.4 分布式文件系统如何提高查询速度?**
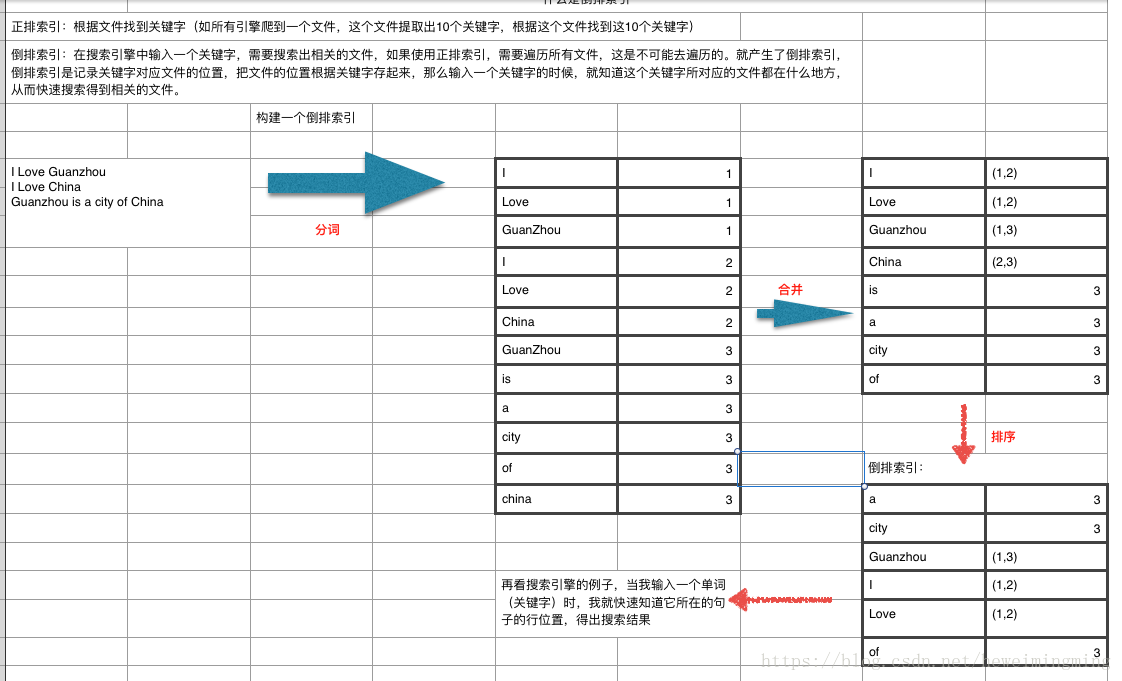
(HDFS 通过倒排索引存储元数据) 采用倒排索引,倒排索引本质上也是索引,那么什么是索引?
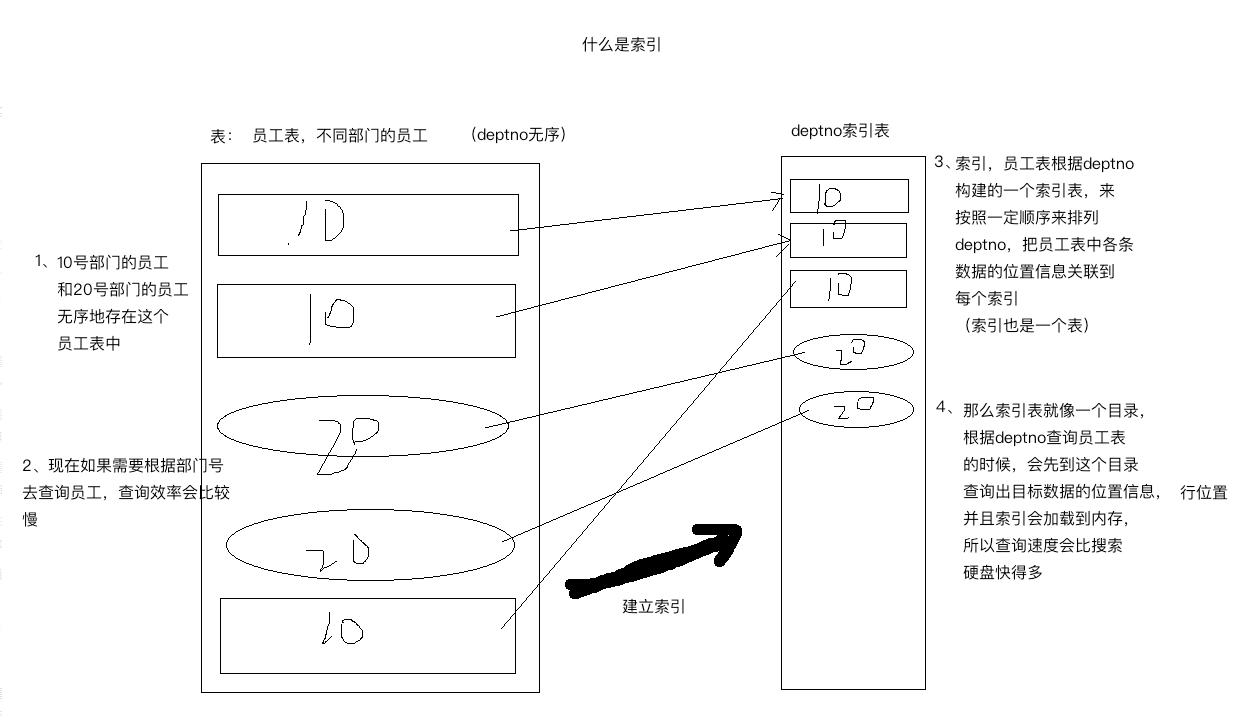
说到倒排索引能联想到正排索引。那么什么是正排索引和倒排索引。通过如下例子来说明:
正排索引:根据文件找到关键字(如所有引擎爬到一个文件,这个文件提取出 10 个关键字,根据这个文件找到这 10 个关键字)
倒排索引:在搜索引擎中输入一个关键字,需要搜索出相关的文件,如果使用正排索引,需要遍历所有文件,这是不可能去遍历的(效率太低)。就产生了倒排索引,倒排索引是记录关键字对应文件的位置,把文件的位置根据关键字存起来,那么输入一个关键字的时候,就知道这个关键字所对应的文件都在什么地方,从而快速搜索得到相关的文件。
如下图例子:
3.2 分布式计算模型
** 3.2.1 来源**
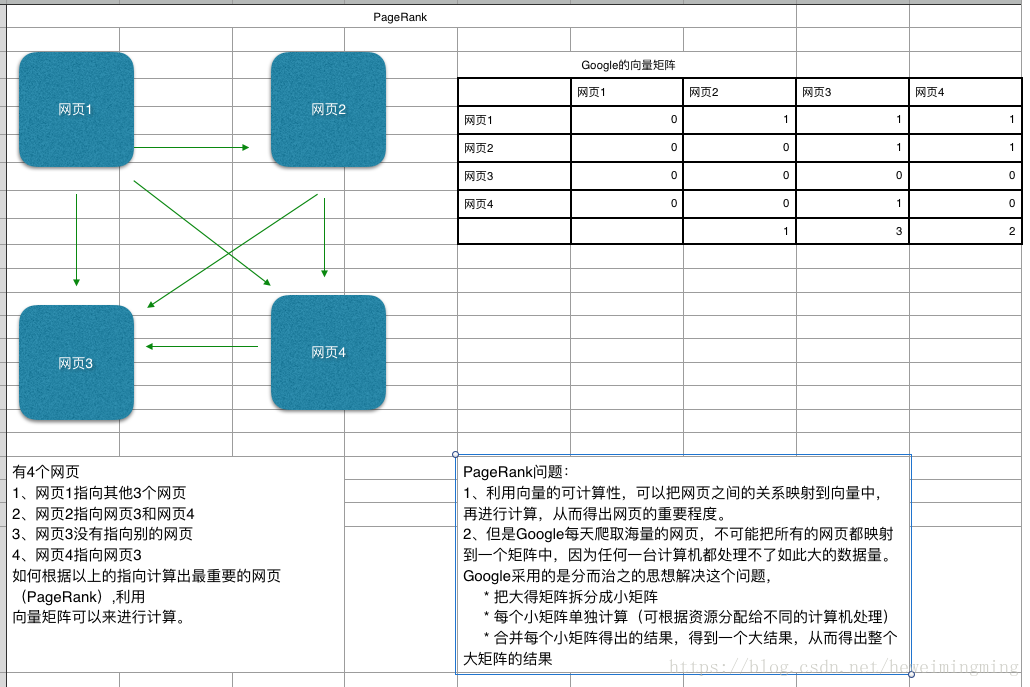
分布式计算模型来源于 PageRank(网页排名)
** 3.2.2 什么是 PageRank?**
Google 每天爬取海量的网页,那么如果按照重要程度来排名网页,应该如何排序? 如下图例子,下图说明的是 4 个网页之间如何排序,核心思想是把网页之间的关系转换成矩阵,因为矩阵是可以计算的,那么可以计算出各个网页的重要程度,用数据来表示,数字越大表示越重要。但是 Google 每天爬取的网页数量是非常庞大的,实际上不可能用一个矩阵来计算,因此分布式计算是来解决这个问题的。核心思想是把一个大的矩阵拆分成很多足够小的矩阵,计算每个小得矩阵,再合并各个小矩阵的结果,从而得出大矩阵的结果,而这个过程是在分布式环境中运行的,如下图:
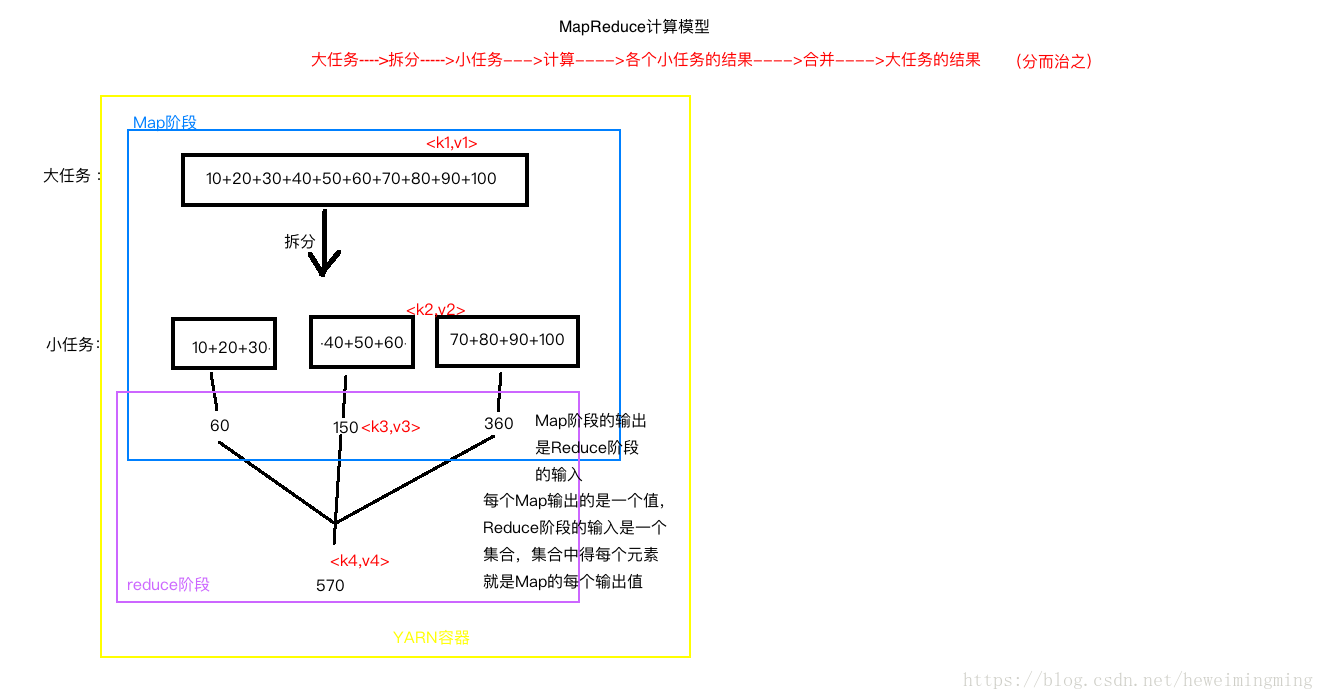
** 3.2.3 分布式计算框架 MapReduce**
关于 MapReduce,有几点需要注意:
- Map 阶段的输出,是 Reduce 阶段的输入。每个 Map 输出的是一个值,Reduce 阶段的输入是一个集合,集合中的每个元素就是 Map 的每个输出值。
- Map 的输入来自 HDFS,Reduce 也输出到 HDFS。
- 图中分别有 4 对 key-value 值。分别是 k1 v1, k2 v2, k3 v3, k4 v4,分别是 Map 的输入,Map 的输出,reduce 的输入,reduce 的输出。
- k2=k3,v2 的类型和 v3 的类型一致。
- MapReduce 所有的输入输出类型必须是 Hadoop 的类型:LongWritable,java 中得 String 对应 Hadoop 中得 Text,java 中得 null 对应 hadoop 中得 NullWritable。
- MapReduce 的输入输出必须实现 hadoop 的序列化,除了原生类型,也可以是自定义类型,但必须实现 hadoop 序列化。
- 从 hadoop2.x 后,MapReduce 程序必须运行在 Yarn 框架中,本地模式除外(本 地模式没有 YARN,也没有 HDFS,本地模式中的 MapReduce 就是一个单一的 java 程序)
3.3 BigTable
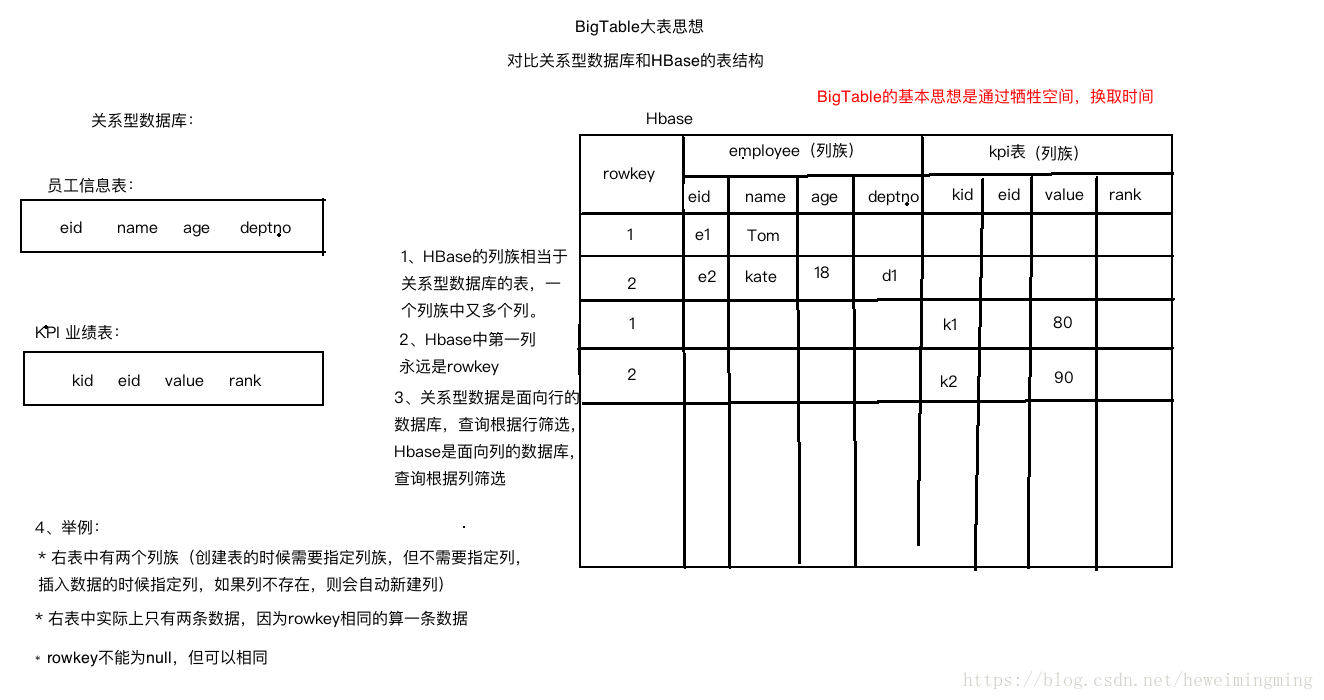
** 3.3.1 大表的基本思想**
把所有数据存入一张表,通过空间换取时间。
** 3.3.2 HBase** HBase 是 hadoop 生态中大表的实现,看下面一个例子,对比数据存储在关系型数据库 Oracle 和 HBase 中
via:
- google 大数据三大论文-中文版-英文版 - 简书 https://www.jianshu.com/p/7df00b383fa1
- Hadoop 起源以及 Google 三篇论文介绍 _hwm 的专栏- CSDN 博客 https://blog.csdn.net/heweimingming/article/details/82177142?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.add_param_isCf
- 什么是大数据?大数据能做什么? | 人人都是产品经理 http://www.woshipm.com/it/2612904.html