mysql数据库删除重复的数据只保留一条
#编程技术 2021-06-28 13:56:02 | 全文 707 字,阅读约需 2 分钟 | 加载中... 次浏览👋 相关阅读
- Excel 纵向查找函数 vlookup() 使用入门
- 三行代码捅穿 CloudFlare 的五秒盾
- MySQL 正则替换数据:REGEXP_REPLACE 函数
- 永久解决 windows powershell 和 CMD 中文显示问号及乱码问题
- MySQL 数据库中随机获取一条或多条记录的三种方法
问题引入
假设一个场景,一张用户表,包含 3 个字段:id,identity_id,name。 现在身份证号 identity_id 和姓名 name 有很多重复的数据,需要删除多余数据只保留一条有效数据。
模拟环境
1、登入 mysql 数据库,创建一个单独的测试数据库 mysql_exercise
create database mysql_exercise charset utf8;
2、创建用户表 users
create table users(
id int auto_increment primary key,
identity_id varchar(20),
name varchar(20) not null
);
3、插入测试数据
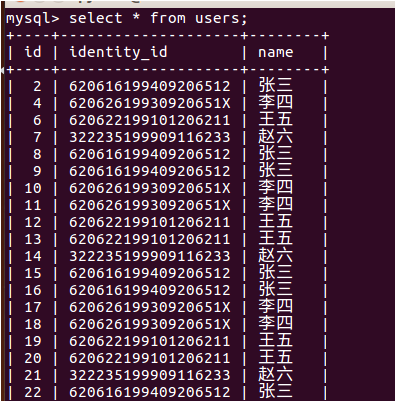
insert into users values(0,'620616199409206512','张三'),
(0,'620616199409206512','张三'),
(0,'62062619930920651X','李四'),
(0,'62062619930920651X','李四'),
(0,'620622199101206211','王五'),
(0,'620622199101206211','王五'),
(0,'322235199909116233','赵六');
可以多执行几次,生成较多重复数据。
4、解决思路
(1)根据身份证号和 name 进行分组; (2)取出分组后的最大 id(或最小 id); (3)删除除最大(或最小)id 以外的其他字段;
方法一:
delete from users where id not in (
select t.max_id from
(select max(id) as max_id from users group by identity_id,name) as t);
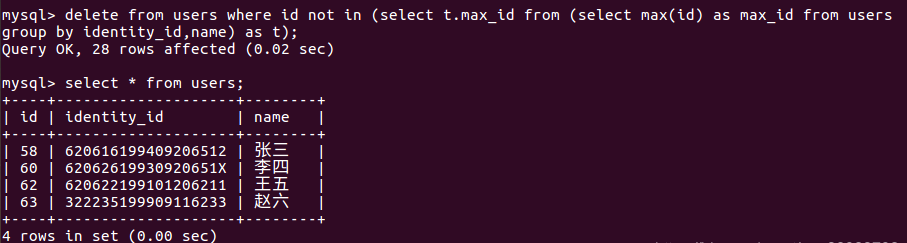
成功将重复的数据删除,只保留了最后一次增加的记录。同理也可以保留第一次添加的记录(即删除每个分组里面除最小 id 以外的其他条记录)
方法二:
delete p1 from users as p1,users as p2
where p1.identity_id = p2.identity_id and p1.name = p2.name and p1.Id > p2.Id;
via
mysql数据库删除重复的数据保留一条_生有涯,知无涯-CSDN博客 https://blog.csdn.net/qq_38923792/article/details/95240733
×
![]()