python:如何从 URL 中快速提取域名?
#编程技术 2020-10-28 14:00:50 | 全文 547 字,阅读约需 2 分钟 | 加载中... 次浏览👋 相关阅读
- Python3.7实现自动刷博客访问量(只需要输入用户id)
- Pycharm 专业版配置自动同步代码至服务器
- 回调函数Callback —从同步思维切换到异步思维
- 让Python在退出时强制运行一段代码
- 脱离苦海,从避免滥用try...except...开始
有时候,我们要从一段很长的 URL 里面提取出域名。例如从https://www.kingname.info/2020/10/02/copy-from-ssh/,我需要获取的是kingname.info。
可能有人会这样写代码:
url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
domain = '.'.join(url.split('/')[2].split('.')[1:])
运行效果如下图所示:

但如果我给出的 URL 没有带 https://,这段代码的结果就有问题。
而且,有些域名可能有三级、四级域名,例如:blog.exercise.kingname.com.cn。显然,使用点分割以后,也不知道怎么拿到真正的域名kingname.com.cn。
还有一些人的需求可能只需要域名中的名字,例如kingname.info只要kingname,google.com.hk只要google。
对于这些需求,如果手动写规则来提取的话,会非常麻烦。
不过好在 Python 有一个第三方库已经解决了这个问题,这就是 tld。
我们先来安装它:
python3 -m pip install tld
安装完成以后,我们来看看它的使用方法:
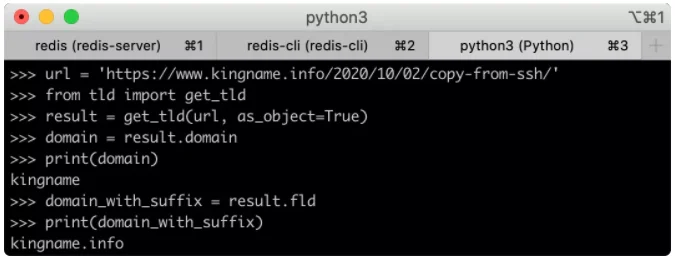
>>> url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
>>> from tld import get_tld
>>> result = get_tld(url, as_object=True)
>>> domain = result.domain
>>> print(domain)
kingname
>>> domain_with_suffix = result.fld
>>> print(domain_with_suffix)
kingname.info
首先使用 get_tld 生成一个对象,然后通过对象的 .domain 属性获得纯域名,使用 .fld 属性,获得带有后缀的域名。
运行效果如下图所示:
对于不含https的网址,直接使用会报错,如下图所示:

但只要加上一个参数fix_protocol=True就可以解决问题:

via:https://mp.weixin.qq.com/s/27mdyBEgP8zWexbAYWOfYw
×
![]()