python:Pandas里千万不能做的5件事
#编程技术 2020-10-28 14:10:51 | 全文 1798 字,阅读约需 4 分钟 | 加载中... 次浏览👋 相关阅读
- python:如何从 URL 中快速提取域名?
- Python3.7实现自动刷博客访问量(只需要输入用户id)
- Pycharm 专业版配置自动同步代码至服务器
- 回调函数Callback —从同步思维切换到异步思维
- 让Python在退出时强制运行一段代码
作为一个在进入数据分析领域之前干过开发的攻城狮,我看到我的同行以及新手在使用 Pandas 时会犯很多低级错误。
今天我说出这五个坑,让大家别一而再,再而三的掉坑里。
修复这些错误能让你的代码逻辑更清晰,更易读,而且把电脑内存用到极致。
错误1:获取和设置值特别慢
这不能说是谁的错,因为在 Pandas 中获取和设置值的方法实在太多了。 大部分时候,你必须只用索引找到一个值,或者只用值找到索引。 然而,在很多情况下,你仍然会有很多不同的数据选择方式供你支配:索引、值、标签等。 在这些不同的方法中,我当然会更喜欢使用当中最快的那种方式。下面列举最慢到最快的常见选择。比如: 测试数据集运行的是 20000 行的 DataFrame
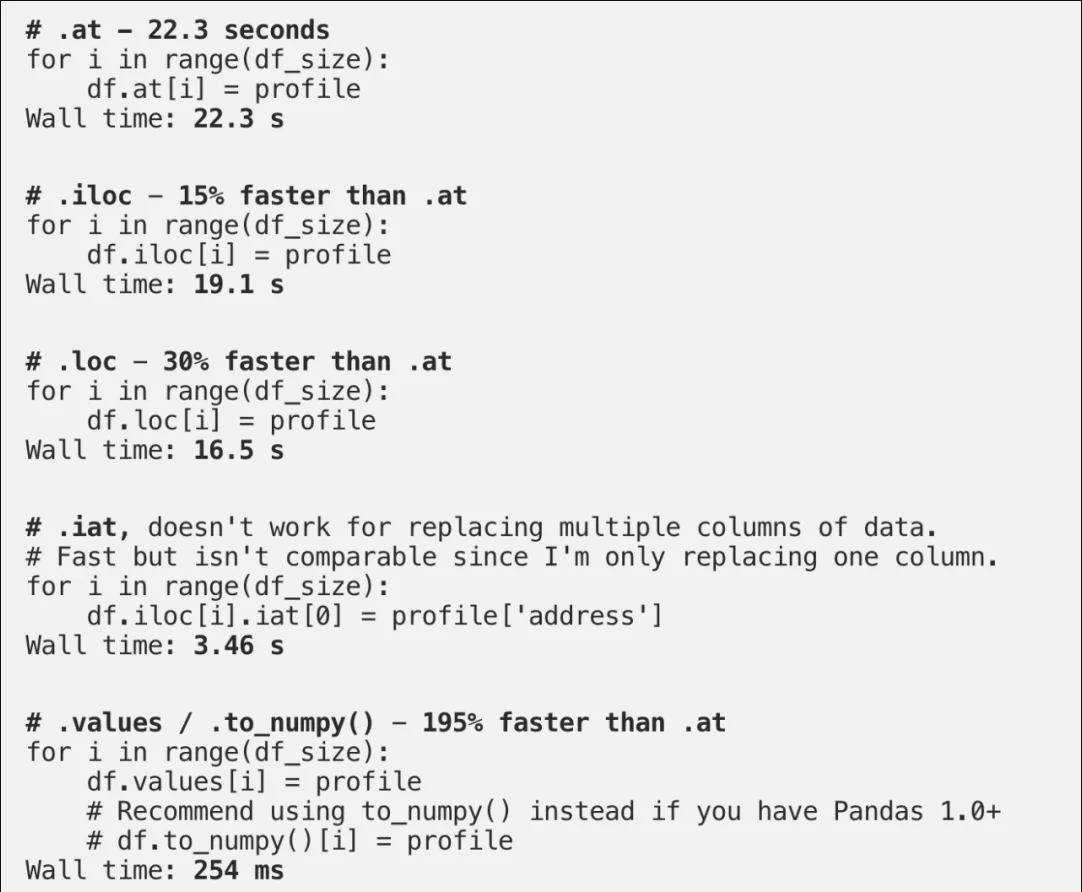
(for循环的慢是显而易见的,看看.apply() 。我在这里使用它们纯粹是为了证明循环内行的速度差异)
错误2:只使用你电脑 CPU 的四分之一
无论你是在服务器上,还是仅仅是你的笔记本电脑,绝大多数人从来没有使用过他们所有的计算能力。 现在大多数处理器(CPU)都有4核,甚至有的是8核。 重点来了!! 默认情况下,Pandas 只使用其中一个核。

怎么办? 用 Modin! Modin 是一个 Python 模块,能够通过更好地利用你的硬件来增强 Pandas 的功能。Modin DataFrames 不需要任何额外的代码,在大多数情况下会将你对 DataFrames 所做的一切加速 3 倍或更多。
Modin 的作用更多的是作为一个插件而不是一个库来使用,因为它使用 Pandas 作为后备,不能单独使用。
Modin 的目标是悄悄地增强 Pandas,让你在不学习新库的情况下继续工作。大多数人需要的唯一一行代码是 import modin.pandas as pd 来取代你正常的 import pandas as pd,但如果你想了解更多,请查看这里的文档(https://modin.readthedocs.io/en/latest/)。
为了避免重新创建已经完成的测试,我从 Modin 文档中加入了这张图片,展示了它在标准笔记本上对 read_csv() 函数的加速作用。请注意,Modin 还在开发中,虽然我在生产中使用它,但不可避免会有一些 bug。请查看 Issues in GitHub 和 Supported API 获取更多信息。
错误3:让Pandas消耗内存来猜测数据类型
当你把数据导入到 DataFrame 中,没有特别告诉 Pandas 列和数据类型时,Pandas 会把整个数据集读到内存中,只是为了弄清数据类型而已。
例如,如果你有一列全是文本的数据,Pandas 会读取每一个值,看到它们都是字符串,并将该列的数据类型设置为 “string”。然后它对你的所有其他列重复这个过程。
你可以使用 df.info() 来查看一个 DataFrame 使用了多少内存,这和 Pandas 仅仅为了弄清每一列的数据类型而消耗的内存大致相同。
除非你在折腾很小的数据集,或者你的列是不断变化的,否则你应该总是指定数据类型。
每次指定数据类型是一个好习惯。
为了做到这一点,只需添加 dtypes 参数和一个包含列名及其数据类型的字符串的字典。比如说:

对于不是来自 CSV 的 DataFrames 也同样的适用。
错误4:将DataFrames遗留到内存中
DataFrames 最好的特性之一就是它们很容易创建和改变。但不幸的副作用是,大多数人最终会得到这样的代码:

发生的情况是你把 df2 和 df1 留在 Python 内存中,即使你已经转移到 df3。不要把多余的 DataFrames 留在内存中,如果你使用的是笔记本电脑,它差不多会损害你所做的所有事情的性能。
如果你是在服务器上,它正在损害该服务器上其他所有人的性能(或者在某些时候,你会得到一个 “内存不足 “的错误)。
与之相反的是,这里有一些简单的方法来保持你的内存不超负荷:
- 使用
df.info()查看 DataFrame 使用了多少内存。 - 在 Jupyter 中安装插件支持。安装 Jupyter 的变量检查器插件。如果你习惯于在 R-Studio 中使用变量检查器,那么你应该知道 R-Studio 现在支持 Python了。如果你已经在 Jupyter 会话中,你可以通过使用 della-dreamer 抹去变量而无需重启。
- 如果您已经在 Jupyter 会话中,您可以随时在不重启的情况下擦除变量,使用 del df2 。
- 在一行中把多个 DataFrame 修改链在一起(只要不使你的代码不可读):
df = df.apply(something).dropna() - 正如国外大牛 Roberto Bruno Martins 指出的,另一种确保内存干净的方法是在函数中执行操作。
错误5:手动配置Matplotlib
这可能是最常见的错误了,把它排在第 5 位,是因为它的影响最小。我看到这个错误甚至会发生在经验丰富的专业人士的博客文章之中。
Matplotlib 是由 Pandas 自动导入的,它甚至会在每个 DataFrame 上为你设置一些图表配置。既然已经为你在 Pandas 中内置了它,那就没有必要再为每张图表导入和配置了。
下面是一个错误的例子,虽然这是一个基本的图表,但还是很浪费代码。

而正确的方法是这样的:
df['x'].plot()
这样更简单吧?你可以在这些 DataFrame 绘图对象上做任何你可以对其他 Matplotlib 绘图对象做的事情。比如:
df['x'].plot.hist(title='Chart title')
via:https://mp.weixin.qq.com/s/VdgfTByQ16kminqcnW6ZKw