阿里巴巴 MySQL binlog 增量订阅 & 消费组件 Canal 实践
#编程技术 2020-11-18 14:39:34 | 全文 3972 字,阅读约需 8 分钟 | 加载中... 次浏览👋 相关阅读
- Python 连接 Oracle 数据库时遇到的坑及解决办法
- loguru 简单方便的 Python 日志记录管理模块
- No 1. 什么是 Pandas & Pandas 能干啥?
- python:Pandas里千万不能做的5件事
- python:如何从 URL 中快速提取域名?
背景
最近有个需求,有多个库,每个库中有一张相同表名的表需要实时同步到另一个服务器上的 Mysql,本想自己 python 写一个脚本去处理,就这么巧,正好看到了阿里巴巴开源的 Canal,刚刚好他又满足需求,那就勉为其难试用一下叭

Canal 是个啥
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
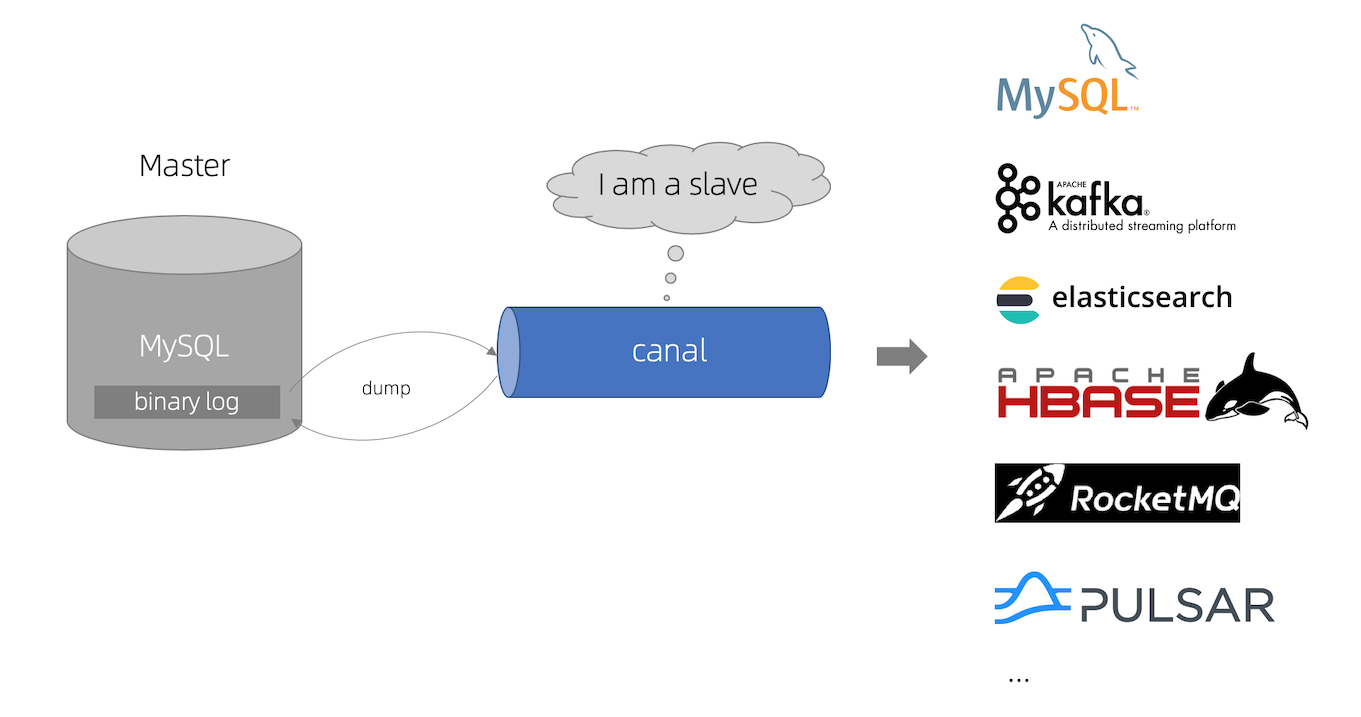
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
canal 的工作原理就是把自己伪装成 MySQL slave,模拟 MySQL slave 的交互协议向 MySQL Mater 发送 dump 协议,MySQL mater 收到 canal 发送过来的 dump 请求,开始推送 binary log 给 canal,然后 canal 解析 binary log,再发送到存储目的地,比如 MySQL,Kafka,Elastic Search 等等。
这里我们可以简单地把 canal 理解为一个用来同步增量数据的一个工具,分为服务端和客户端。
与其问 canal 能做什么,不如说数据同步有什么作用。
canal 的数据同步不是全量的,而是增量。基于 binary log 增量订阅和消费,canal 可以做:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
更多的介绍看官方吧 -> https://github.com/alibaba/canal
搞起
接下来咱们就跟着官方的步骤一步一步踩坑叭
Mysql 配置
既然是依靠 Mysql 的 binlog 日志,那 binlog 必然是要打开的,怎么看打没打开?
show variables like 'log_bin';
执行上面的 sql 语句,如果返回 on 那就是开喽

当然只是打开还不够,还需要配置 binlog-format 为 ROW 模式,所以不管打没打开,都打开 my.cnf 配置搂一眼喽,Linux 一般情况下配置文件在 /etc/my.cnf,如果使其它系统,自己找!
打开配置文件,怕改错了可以先备份一下
vi /etc/my.cnf
在配置文件 mysqld 下添加如下配置,如果已经有的就忽略叭
[mysqld]
log-bin=mysql-bin ## 开启 binlog
binlog-format=ROW ## 选择 ROW 模式
server_id=1 ## 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
配置修改完之后重启下数据库,然后再用上边命令查看下 binlog 打开没,如果还没有打开,那就找找自己原因
接下来就是新建一个 canal 账号并授权
// 创建账号,账号名为:canal,密码:自己设置
CREATE USER canal IDENTIFIED BY '密码';
// 授权
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
// 刷新MySQL的系统权限相关表
FLUSH PRIVILEGES;
搞完自己登陆试一下啦,能正常登录就接着往下走
查看当前正在写入的 binlog 文件,下边配置信息里要用
show master status;
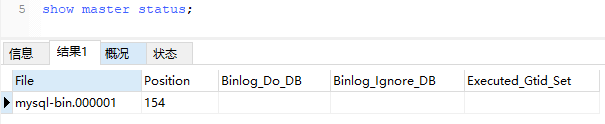
查询 binlog 偏移量(Pos 字段),看你需求,可以不用
mysql> show binlog events in 'mysql-bin.000001';
+------------------+------+-------------+-----------+-------------+-----------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+------+-------------+-----------+-------------+-----------------------------------------------------------+
| mysql-bin.000001 | 4 | Format_desc | 195 | 106 | Server ver: 5.1.73-log, Binlog ver: 4 |
| mysql-bin.000001 | 106 | Query | 195 | 198 | use `hadoop`; delete from user where id=3 |
| mysql-bin.000001 | 198 | Intvar | 195 | 226 | INSERT_ID=4 |
| mysql-bin.000001 | 226 | Query | 195 | 332 | use `hadoop`; INSERT INTO user (id,name)VALUES (NULL,1) |
| mysql-bin.000001 | 332 | Query | 195 | 424 | use `hadoop`; delete from user where id=3 |
| mysql-bin.000001 | 424 | Intvar | 195 | 452 | INSERT_ID=5 |
| mysql-bin.000001 | 452 | Query | 195 | 560 | use `hadoop`; INSERT INTO user (id,name)VALUES (NULL,222) |
| mysql-bin.000001 | 560 | Query | 195 | 660 | use `hadoop`; DELETE FROM `user` WHERE (`id`='1') |
| mysql-bin.000001 | 660 | Intvar | 195 | 688 | INSERT_ID=6 |
| mysql-bin.000001 | 688 | Query | 195 | 795 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('555') |
| mysql-bin.000001 | 795 | Intvar | 195 | 823 | INSERT_ID=7 |
| mysql-bin.000001 | 823 | Query | 195 | 930 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('555') |
| mysql-bin.000001 | 930 | Intvar | 195 | 958 | INSERT_ID=8 |
| mysql-bin.000001 | 958 | Query | 195 | 1065 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('555') |
| mysql-bin.000001 | 1065 | Intvar | 195 | 1093 | INSERT_ID=9 |
| mysql-bin.000001 | 1093 | Query | 195 | 1200 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('555') |
| mysql-bin.000001 | 1200 | Query | 195 | 1300 | use `hadoop`; DELETE FROM `user` WHERE (`id`='9') |
| mysql-bin.000001 | 1300 | Query | 195 | 1400 | use `hadoop`; DELETE FROM `user` WHERE (`id`='8') |
| mysql-bin.000001 | 1400 | Query | 195 | 1500 | use `hadoop`; DELETE FROM `user` WHERE (`id`='7') |
| mysql-bin.000001 | 1500 | Query | 195 | 1600 | use `hadoop`; DELETE FROM `user` WHERE (`id`='4') |
| mysql-bin.000001 | 1600 | Query | 195 | 1700 | use `hadoop`; DELETE FROM `user` WHERE (`id`='5') |
| mysql-bin.000001 | 1700 | Query | 195 | 1800 | use `hadoop`; DELETE FROM `user` WHERE (`id`='6') |
| mysql-bin.000001 | 1800 | Intvar | 195 | 1828 | INSERT_ID=10 |
| mysql-bin.000001 | 1828 | Query | 195 | 1935 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('555') |
| mysql-bin.000001 | 1935 | Intvar | 195 | 1963 | INSERT_ID=11 |
| mysql-bin.000001 | 1963 | Query | 195 | 2070 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('666') |
| mysql-bin.000001 | 2070 | Intvar | 195 | 2098 | INSERT_ID=12 |
| mysql-bin.000001 | 2098 | Query | 195 | 2205 | use `hadoop`; INSERT INTO `user` (`name`) VALUES ('777') |
+------------------+------+-------------+-----------+-------------+-----------------------------------------------------------+
安装 Canal 服务端
首先下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.0.17 版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.0.17/canal.deployer-1.0.17.tar.gz
解压缩
mkdir /tmp/canal
tar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
解压完成后,进入 /tmp/canal 目录,可以看到如下结构
drwxr-xr-x 2 root root 136 2013-02-05 21:51 bin
drwxr-xr-x 4 root root 160 2013-02-05 21:51 conf
drwxr-xr-x 2 root root 1.3K 2013-02-05 21:51 lib
drwxr-xr-x 2 root root 48 2013-02-05 21:29 logs
配置修改
vi conf/example/instance.properties
配置信息如下,按照你自己的需求修改
### mysql serverId , v1.0.26+ will autoGen
### v1.0.26版本后会自动生成slaveId,所以可以不用配置
## canal.instance.mysql.slaveId=0
## 数据库地址
canal.instance.master.address=127.0.0.1:3306
## binlog日志名称,上边查出来的 binlog 日志文件名
canal.instance.master.journal.name=mysql-bin.000001
## mysql主库链接时起始的binlog偏移量,如果不需要偏离就不用填
canal.instance.master.position=2098
## mysql主库链接时起始的binlog的时间戳,同上
canal.instance.master.timestamp=
canal.instance.master.gtid=
## username/password
## 在MySQL服务器授权的账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
## 字符集
canal.instance.connectionCharset = UTF-8
## enable druid Decrypt database password
canal.instance.enableDruid=false
## table regex .*\\..* 表示监听所有表 也可以写具体的表名,用,隔开,我这里需要监控所有库 wangtwothree_ 开头的表,配置如下
canal.instance.filter.regex=.*\\.wangtwothree_.*
## mysql 数据解析表的黑名单,多个表用,隔开
canal.instance.filter.black.regex=
- canal.instance.connectionCharset 代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-
- 如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
canal.instance.filter.regex 的书写格式:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
更多介绍看文档 -> https://github.com/alibaba/canal/wiki/AdminGuide
启动
配置完成,接下来就是喜闻乐见的启动环节了
sh bin/startup.sh
查看 server 日志
vi logs/canal/canal.log
2020-11-17 22:45:27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ### start the canal server. 2020-11-17 22:45:28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ### start the canal server[10.1.29.120:11111] 2020-11-17 22:45:28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ### the canal >server is running now ……
查看 instance 的日志
vi logs/example/example.log
2020-11-17 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties] 2020-11-17 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties] 2020-11-17 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example 2020-11-17 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start >successful….
查看 logs/canal/canal.log
vi logs/canal/canal.log
2020-11-17 22:52:41.724 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ### set default uncaught exception handler 2020-11-17 22:52:41.744 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ### load canal configurations 2020-11-17 22:52:41.778 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ### start the canal server. 2020-11-17 22:52:41.838 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ### start the canal server[192.168.0.110(192.168.0.110):11111] 2020-03-24 19:50:43.489 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ### the canal server is running now ……
注意
如果要从最新位置记录数据库的 binlog,可以删除 conf/example/meta.dat文件。
嗯,一切正常,风平浪静,服务端这就配置完成了
关闭
这里只是告诉你关闭命令,你如果没有问题正常使用就不要关闭啊喂
sh bin/stop.sh
客户端搞一哈
客户端可以理解为某种意义上的数据库客户端,通过一些简单的编码,我们可以获取存在 canal 服务端的已被解析的 binlog 数据(增量数据),获取数据以后,即可进行定制化的处理。
客户端支持的语言还是挺多的,自己挑一个吧
canal java 客户端: https://github.com/alibaba/canal/wiki/ClientExample canal c## 客户端: https://github.com/dotnetcore/CanalSharp canal go客户端: https://github.com/CanalClient/canal-go canal php客户端: https://github.com/xingwenge/canal-php canal Python客户端:https://github.com/haozi3156666/canal-python canal Rust客户端:https://github.com/laohanlinux/canal-rs

这里我就用 Python 来测试啦,毕竟别的也不熟
本次采用的是由个人开发的 python 客户端,github 主页:https://github.com/haozi3156666/canal-python
环境要求
python >= 3
构建 canal python 客户端
pip install canal-python
建立与Canal的连接
import time
from canal.client import Client
from canal.protocol import EntryProtocol_pb2
from canal.protocol import CanalProtocol_pb2
## 建立与canal服务端的连接
client = Client()
client.connect(host='127.0.0.1', port=11111) ## canal服务端部署的主机IP与端口
client.check_valid(username=b'', password=b'') ## 自行填写配置的数据库账户密码
## destination是canal服务端的服务名称, filter即获取数据的过滤规则,采用正则表达式
client.subscribe(client_id=b'1001', destination=b'example', filter=b'.*\\..*')
while True:
message = client.get(100)
## entries是每个循环周期内获取到数据集
entries = message['entries']
for entry in entries:
entry_type = entry.entryType
if entry_type in [EntryProtocol_pb2.EntryType.TRANSACTIONBEGIN, EntryProtocol_pb2.EntryType.TRANSACTIONEND]:
continue
row_change = EntryProtocol_pb2.RowChange()
row_change.MergeFromString(entry.storeValue)
event_type = row_change.eventType
header = entry.header
## 数据库名
database = header.schemaName
## 表名
table = header.tableName
event_type = header.eventType
## row是binlog解析出来的行变化记录,一般有三种格式,对应增删改
for row in row_change.rowDatas:
format_data = dict()
## 根据增删改的其中一种情况进行数据处理
if event_type == EntryProtocol_pb2.EventType.DELETE:
format_data['before'] = dict()
for column in row.beforeColumns:
#format_data = {
## column.name: column.value
#}
#此处注释为原demo,有误,下面是正确写法
format_data['before'][column.name] = column.value
elif event_type == EntryProtocol_pb2.EventType.INSERT:
format_data['after'] = dict()
for column in row.afterColumns:
#format_data = {
## column.name: column.value
#}
#此处注释为原demo,有误,下面是正确写法
format_data['after'][column.name] = column.value
else:
## format_data['before'] = format_data['after'] = dict() 采用下面的写法应该更好
format_data['before'] = dict()
format_data['after'] = dict()
for column in row.beforeColumns:
format_data['before'][column.name] = column.value
for column in row.afterColumns:
format_data['after'][column.name] = column.value
## data即最后获取的数据,包含库名,表明,事务类型,改动数据
data = dict(
db=database,
table=table,
event_type=event_type,
data=format_data,
)
print(data)
time.sleep(1)
client.disconnect()
使用数据
这个 demo 间隔一秒获取一次服务端的增量数据,并作相应的解析,代码中我已经做了简单的注释帮助理解,最后获取的 data 就是某个 sql 语句改动某一行的完整记录,通常有三种情况:
## 设库test中有表test1,分别有id(int)和name(varchar)字段
## insert操作:insert into test.test1 values (1,'a')
## 此时data中应是如下情况
data = {'db':'test', 'table':'test1', 'event_type':1, 'data':{'after':{'id':'1', 'name':'a'}}}
## update操作:update test.test1 set id=2, name='b' where id=1
## 此时的data
data = {'db':'test', 'table':'test1', 'event_type':2, 'data':{'before':{'id':'1', 'name':'a'}, 'after':{'id':'2', 'name':'b'}}}
## delete操作:delete from test.test1 where id=2
## 此时的data
data = {'db':'test', 'table':'test1', 'event_type':3, 'data':{'before':{'id':'2', 'name':'b'}}}
注意:通过上面的代码可以看出无论原始数据是 int 还是 varchar,解析出来的数据都是字符串类型;
如上,可根据生成的 data 做进一步处理,有较大的自由度,而此处我需要的是直接插入到另一台主机上的同样的库表中,因此我需要将 data 再解析为 sql 语句:
def data_to_sql(data: dict) -> str:
db = data['db']
table = data['db']
sql = ''
## insert
if data['event_type'] == 1:
dic_data = data['data']['after']
insert_value = ""
for key in dic_data.keys():
insert_value = insert_value + f"'{dic_data[key]}'" + ','
insert_value = insert_value[:-1]
sql = f"insert into {db}.{table} values ({insert_value});"
return sql
## update
elif data['event_type'] == 2:
before_data = data['before']
after_data = data['after']
update_value = ""
update_condition = ""
for key in before_data.keys():
update_condition = update_condition + f"'{before_data[key]}' and "
update_condition = update_condition[:-5]
for key in after_data.keys():
update_value = update_value + key + f"='{after_data[key]}',"
update_value = update_value[:-1]
sql = f"update {db}.{table} set {update_value} where {update_condition};"
## delete
else:
dic_data = data['data']['before']
delete_condition = ""
for key in dic_data.keys():
delete_condition = delete_condition + f"'{dic_data[key]}' and "
delete_condition = delete_condition[:-5]
sql = f"delete from {db}.{table} where {delete_condition};"
return sql
OK,到这里就顺利完成需求啦,下班碎觉
via:
- alibaba/canal: 阿里巴巴 MySQL binlog 增量订阅&消费组件 https://github.com/alibaba/canal
- Canal监控MySQL数据库实现数据同步_lqbz456的博客-CSDN博客 https://blog.csdn.net/lqbz456/article/details/105079022?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~top_click~default-1-105079022.nonecase&utm_term=canal%E7%9B%91%E6%8E%A7mysql&spm=1000.2123.3001.4430
- python进行mysql数据实时同步的正确姿势(使用canal) - 知乎 https://zhuanlan.zhihu.com/p/165428937
- haozi3156666/canal-python: alibaba canal 客户端(Python3 版本) https://github.com/haozi3156666/canal-python
- 超详细的Canal入门,看这篇就够了!_yehongzhi1994的博客-CSDN博客_canal https://blog.csdn.net/yehongzhi1994/article/details/107880162
- mysql查看binlog日志内容_Arthas的博客-CSDN博客 https://blog.csdn.net/liqihang_dev/article/details/84873579?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduend~default-2-84873579.nonecase&utm_term=mysql%20%E5%81%8F%E7%A7%BB%20%E6%9F%A5%E7%9C%8Bbinlog&spm=1000.2123.3001.4430